Simplest Guide to DIY Your Own LLM Toy in 2024



2024’s here, and DIY LLM toys? Totally a thing now. No tech wizardry needed, just your curiosity. I took the plunge, mixing a bit of coding with heaps of fun, and bam — created my own talking toy. If you’re up for crafting an AI buddy with ease, you’re in the right spot. Let’s demystify tech together and bring your AI friend to life. In a world where technology increasingly intersects with daily life, creating your own LLM toy not only demystifies AI but also provides a personalized gateway to the wonders of interactive technology.
Let’s take a look at the final effect first.
https://www.youtube.com/embed/FKEYL6VgHo4
Honestly, it’s pretty awesome. Ready to start? Let’s dive in!
How Does It Work?
There are three key steps:
Recording: Receive real-time recording data sent by the toy through UDP, and call the STT (Sound-To-Text) API to convert the sound into text.
Thinking: After receiving the previous text, the LLM (Large-Language-Model) API will be immediately called to obtain sentences generated by the LLM in a streaming manner. Then, the TTS (Text-To-Sound) API is called to convert the sentences into human speech.
Play audio: Toys will receive TTS (Text-To-Sound) audio file streams generated by the FoloToy Server and play them according to the order.
Preparation Before Development
Before you start making your LLM toy, it is crucial to understand the necessary hardware, software, and technical knowledge. This section will guide you in preparing all the essentials to ensure a smooth start.
Hardware

Folotoy Core: The ChatGPT AI Voice Conversation Core Board serves as the brain of your project, enabling voice interactions with AI.

Toy Components: Essentials like a microphone, speaker, buttons, switches, and power supply are necessary. I’m going with the Alilo Honey Bunny G6 for its ready-to-use setup.

Octopus Dev Suit (Other Chooise): Ideal for those looking to retrofit existing toys with AI capabilities.
When making purchase, provide my promo code F-001–18 to receive a discount.
Server
Utilizing your own machine, like a MacBook Pro, ensuring that your toy has a reliable backend to process and respond to voice interactions. Alternatively, cloud services like Google Cloud Engine (GCE) can scale your project for broader applications.
Knowledge
Docker (required): Understanding Docker is crucial for deploying software in containers, making your project portable and scalable. I use it for start Folo server.
Git (required): Version control is essential for managing your project’s codebase. I use it for managing the Folo server codebase.
MQTT (optional): If you’re aiming for advanced customization, familiarity with MQTT (a lightweight messaging protocol) will be beneficial for communicating between the toy and the server.
EMQX (optional): Open-source MQTT broker for IoT, IIoT, and connected vehicles. Used for managing your toys.
ollama (optional): If you want to run large language models locally, it’s a good chooise.
Services & Registration
To make your toy come to life, you’ll need access to specific AI services. For this project, I’ve chosen to utilize OpenAI’s offerings:
TTS (Text-to-Speech): OpenAI’s Whisper service converts text responses from the AI into speech, making the interaction natural.
LLM (Large Language Model): Utilizing OpenAI’s models for understanding and generating human-like text responses.
STT (Speech-to-Text): OpenAI’s TTS service transcribes spoken words into text, allowing the AI to understand voice commands or queries.
The most important thing is that you need to register on the OpenAI platform and create a key, like sk-…i7TL.
Assemble Your Toy
Now it’s time to put all the pieces together and make your own LLM toy.
The general steps are as follows, it is recommended to watch the video tutorial first.
Check if the recording and playback of Alilo G6 are normal.
Use a screwdriver to unscrew the 6 screws on the back of Alilo G6.
Carefully open the casing of Alilo G6, unplug all plugs on the motherboard, first unplug the power plug, there is glue on the plug, you can use an art knife to gently cut it open, be sure not to cut your hand.
Unscrew the 4 screws on the motherboard and remove it.
Replace the original motherboard with FoloToy’s motherboard and tighten 3 screws to fix it.
Plug in microphone, light, speaker and power sockets, finally plug in power socket.
After plugging in all sockets, do not close the casing or install screws yet. First turn on/off switch on rabbit’s tail to see if newly installed light can turn on and flash slowly in blue color.
If there is no problem, install the casing and tighten screws to complete replacement process.
Set Up the Server
A strong backend support is key to making your LLM toys understand and respond to voice commands. This section will teach you how to clone the server code base, configure the server, and start Docker containers to ensure that your toys have stable backend support.
First clone the Folo server codebase from GitHub.
git clone git@github.com:FoloToy/folotoy-server-self-hosting.git
Then change the base server configuration in file docker-compose.yml to your own.
| Name | Description | Example |
| ---------------------- | ------------------------------ | ------------------------- |
| OPENAI_OPENAI_KEY | Your OpenAI API key. | sk-...i7TL |
| OPENAI_TTS_KEY | Your OpenAI API key. | sk-...i7TL |
| OPENAI_WHISPER_KEY | Your OpenAI API key. | sk-...i7TL |
| AUDIO_DOWNLOAD_URL | The URL of the audio file. | http://192.168.x.x:8082 |
| SPEECH_UDP_SERVER_HOST | The IP address of your server. | 192.168.x.x |
Then configure your roles in the config/roles.json file, here is a minimal example, for full configuration, please refer to the Folotoy documentation.
{
"1": {
"start_text": "Hello, what can I do for you?",
"prompt": "You are a helpful assistant."
}
}
Then start the docker containers.
docker compose up -d
I run the Folo server in my own machine, if you want to run it in the cloud, almost the same. One thing to note is that you need to expose the port 1883, 8082, 8085, 18083 and 8083 to the public network.
For more information, please refer to the Folotoy documentation.
Chat with Your Toy
Once everything is ready, it’s time to interact with your LLM toy.
Turn on the switch on the back of the toy to power it on. The blue blinking light in the ears indicates that the toy has entered pairing mode.
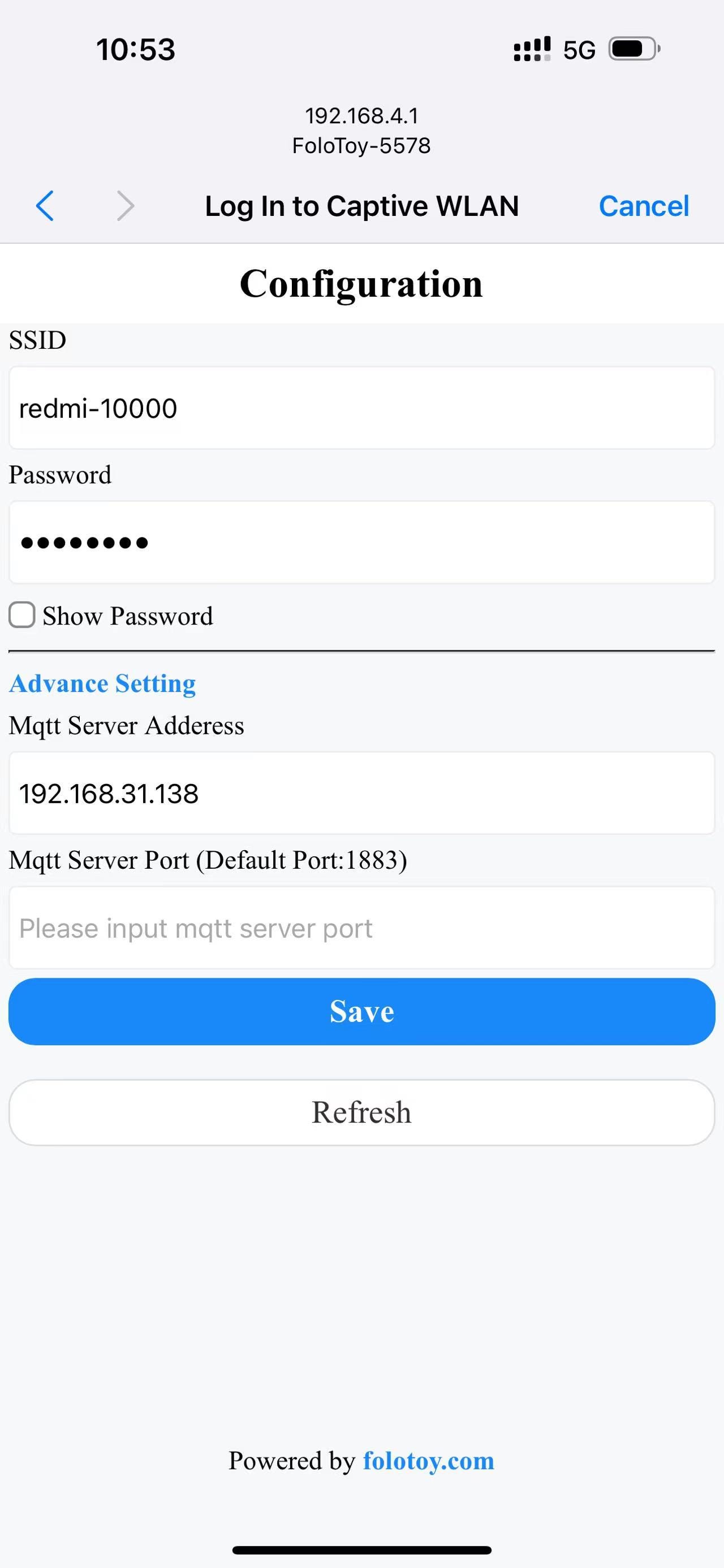
Turn on your phone or computer, and select the “FoloToy-xxxx” wireless network. After a moment, your phone or computer will automatically open a configuration page where you can set which WiFi network (SSID and password) to connect to, as well as the server address (like 192.168.x.x) and port number (keep the default 1883).
After the network is configured and connected to the server, press the big round button in the middle to start the conversation. After you stop speaking, FoloToy will emit a beep to indicate the end of the recording.
The 7 round small buttons around are role switching buttons. After clicking, the role switch takes effect.
Debugging
Whether it is a server or a toy, you may encounter some technical problems. This section will provide some basic debugging tips and tools to help you diagnose and solve possible problems and ensure that your LLM toys can run smoothly.
Server Debugging
To check the server logs, run the following command.
docker compose logs -f
LOG_LEVEL can be set in the docker-compose.yml file to control the log level.
Toy Debugging
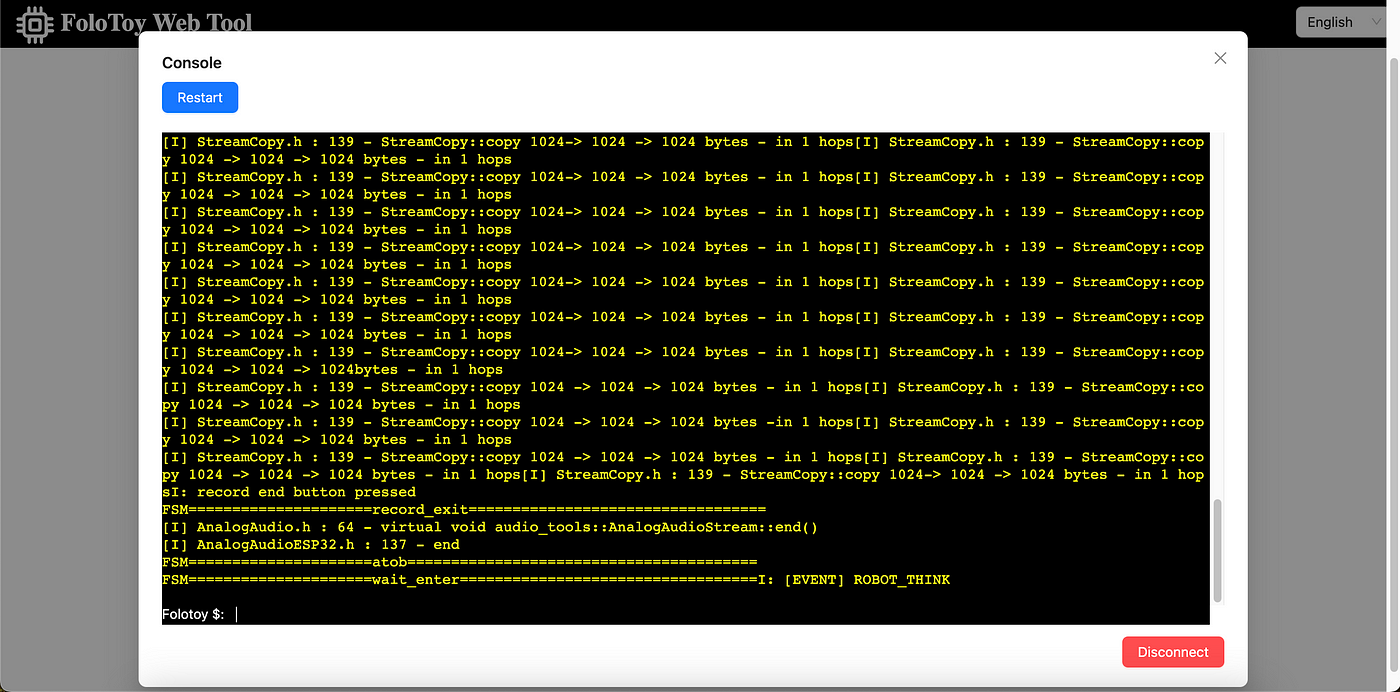
Folo Toy provides a easy way to debug the toy base on USB serial port. You can use the Folo Toy Web Tool to debug the toy.
Connect the toy with your computer using a USB cable.
Open the Folo Toy Web Tool, and then click the “Console” button to connect to the toy.
Once connected, you should be able to see real-time logs from your device in the console.
Also there is a LED on the toy, it will light up in different colors to indicate the status of the toy.
MQTT Debugging
Open the EMQX Dashboard to check the MQTT messages. The default username is admin and the password is public. Anyways, change the password to a secure one after you log in.
Advanced Customization
For advanced users who want to further explore and customize their LLM toys, this section will introduce how to locally run large language models, use tools such as CloudFlare AI Gateway, and customize the voice of characters. This will open up a broader world of DIY LLM toys for you.
Run LLM Locally

Running large language models locally is a interesting thing. You can run Llama 2, Gemma and all kinds of open-source large models from around the world, even models trained by yourself. Using ollama, you can do it easily. Install ollama first, and then run the following command to run the Llama 2 model.
ollama run llama2
Then, change the role configuration to use the local LLM model.
{
"1": {
"start_text": "Hello, what can I do for you?",
"prompt": "You are a helpful assistant.",
"llm_type": "ollama",
"llm_config": {
"api_base": "http://host.docker.internal:11434",
"model": "llama2"
}
}
}
The api_base should be the address of your ollama server address, and don’t forget to restart the Folo server to make the changes take effect.
docker compose restart folotoy
That’s all, change model to Gemma or other models as you like, and enjoy it.
Use CloudFlare AI Gateway
Cloudflare’s AI Gateway allows you to gain visibility and control over your AI apps. By connecting your apps to AI Gateway, you can gather insights on how people are using your application with analytics and logging and then control how your application scales with features such as caching, rate limiting, as well as request retries, model fallback, and more.
First, you need to create a new AI Gateway.
Then edit the docker-compose.yml file to change OPENAI_OPENAI_API_BASE to the address of your AI Gateway, like this:
services:
folotoy:
environment: OPENAI_OPENAI_API_BASE=https://gateway.ai.cloudflare.com/v1/${ACCOUNT_TAG}/${GATEWAY}/openai

Then you have a dashboard to see metrics on requests, tokens, caching, errors, and cost.

And a logging page to see individual requests, such as the prompt, response, provider, timestamps, and whether the request was successful, cached, or if there was an error.
That’s fantastic, isn’t it?
Role Voice Costomization
You can customize the voice of the role by changing the voice_name field in the role configuration file.
{
"1": {
"tts_type": "openai-tts",
"tts_config": {
"voice_name": "alloy"
}
}
}
Find the voice you like in the OpenAI TTS Voice List.
Edge tts has many voices to choose from, enjoy it like this:
{
"1": {
"tts_type": "edge-tts",
"tts_config": {
"voice_name": "en-NG-EzinneNeural"
}
}
}
Knowledge base support

For higher levels of customization, such as knowledge base support. It is recommended to use Dify, which combines the concepts of Backend as Service and LLMOps, covering the core technology stack required to build generative AI native applications, including a built-in RAG engine. With Dify, you can self-deploy capabilities like Assistants API and GPTs based on any model.
Let’s focus on the built-in RAG engine, which is a retrieval-based generative model that can be used for tasks such as question and answer, dialogue, and document summarization. Dify includes various RAG capabilities based on full-text indexing or vector database embedding, allowing direct upload of various text formats such as PDF and TXT. Upload your knowledge base, so you don’t have to worry about the toy making nonsense because you don’t know the background knowledge.
Dify can be deployed by itself or use the cloud version directly. The configuration on Folo is also very simple:
{
"1": {
"llm_type": "dify",
"llm_config": {
"api_base": "http://192.168.52.164/v1",
"key": "app-AAAAAAAAAAAAAAAAAAa"
}
}
}
Custom toy shape

In terms of working principle, any toy can be modified. Folo Toy also offers the Octopus AI Development Kit, which can transform any ordinary toy into an intelligent talking toy. The chip is small and lightweight and can easily fit into any type of toy, whether plush, plastic, or wooden.

I DIYed a Shaanxi-speaking cactus. Use your imagination, you can put it into your favorite toys, and it’s not particularly complicated to do it:
open the toy
Put the Octopus AI development kit into it
close the toy
The server still uses the same one. You can assign different roles to different toys through sn, which will not be expanded here. You can check the configuration document on the official website.
Security Notes
Please note, never put the key in a public place, such as GitHub, or it will be abused. If your key is leaked, delete it immediately on the OpenAI platform and generate a new one.
You can also use environment variables in docker-compose.yml and pass them in when starting the container, so as to avoid exposing the key in the code.
services:
folotoy:
environment:
- OPENAI_OPENAI_KEY=${OPENAI_OPENAI_KEY}
OPENAI_OPENAI_KEY=sk-...i7TL docker compose up -d
In case you wish to make FoloToy Server publicly available on the Internet, it is strongly recommended to secure the EMQX service and allow access to EMQX only with a password. Learn more about EMQX Security.
Conclusion
Crafting your own LLM toy is an exciting journey into the world of AI and technology. Whether you’re a DIY enthusiast or a beginner, this guide provides the roadmap to create something truly interactive and personalized. If you encounter challenges acquiring the Folotoy Core or face any issues along the way, joining our Telegram group offers community support and expert advice.

For those preferring a ready-made solution, the finished product is available for purchase here. This option delivers the same interactive experience without the need for assembly. Folo toys also offer many other products which can be found here. This is their store address:
Purchase Folo Toy products now and enjoy discounts by providing my promo code, F-001–18, when contacting customer service. You can save 20 RMB on the Fofo G6, 15 RMB on the Octopus Dev Suit, and 10 RMB on the cactus. Most other items also qualify for a 10 RMB discount, but please contact customer service to inquire.




Embark on this creative venture to bring your AI companion to life, tapping into the vast potential of LLM toys for education, entertainment, and beyond.
Français: Guide le plus simple pour bricoler votre propre jouet LLM en 2024
Deutsch: Der einfachste Leitfaden zum Selbermachen Ihres eigenen LLM-Spielzeugs im Jahr 2024
Português: Guia mais simples para fazer seu próprio brinquedo LLM em 2024
Español: La guía más sencilla para crear su propio juguete LLM en 2024
Русский: Самое простое руководство по изготовлению собственной игрушки LLM в 2024 году
Italiano: La guida più semplice al fai-da-te del tuo giocattolo LLM nel 2024
हिन्दी: 2024 में अपना खुद का LLM खिलौना बनाने की सबसे सरल मार्गदर्शिका
简体中文: 2024 年自制大语言模型玩具指南
繁體中文: 2024 年 DIY 自己的大语言模型玩具的指南